Every month, I get 200+ pieces of customer feedback across three products with over 1M users combined:
- Support tickets in HelpScout
- Feature requests in ProductLift
- Business metrics in Metabase (aka SQL queries)
- Google Analytics data
And every month, I have to turn all of that into a product plan that my team can actually ship.
The core problem is fragmentation. Support tickets tell me what’s broken. Feature request boards tell me what’s wanted. Business metrics tell me what’s declining.
But the highest-confidence signal is when the same theme shows up independently in multiple places — and nobody is connecting those dots automatically.
I’ve been using AI for product planning for over a year (I wrote about my process in another blog post here). But I was still the one manually pulling data from three different tools, pasting it into Google Docs, and asking Claude to synthesize it.
That workflow worked. But it was slow, it wasn’t repeatable, and it didn’t scale.
MCP has changed my approach completely. Instead of me being the glue between data sources and the LLM, I could build a server that handles the extraction, normalization, and scoring. And then let Claude focus on synthesis and judgment. MCP gives structured tool interfaces with typed parameters, composability between independent servers, and a client that orchestrates everything.
This is also where AI-assisted product management is heading.
The next frontier is Claude reasoning about what to build next by looking at customer feedback, bug reports, and business metrics. pm-copilot is my attempt to build that future today.
So I built pm-copilot — an MCP server that triangulates support tickets, feature requests, and business metrics into a single prioritized product plan.
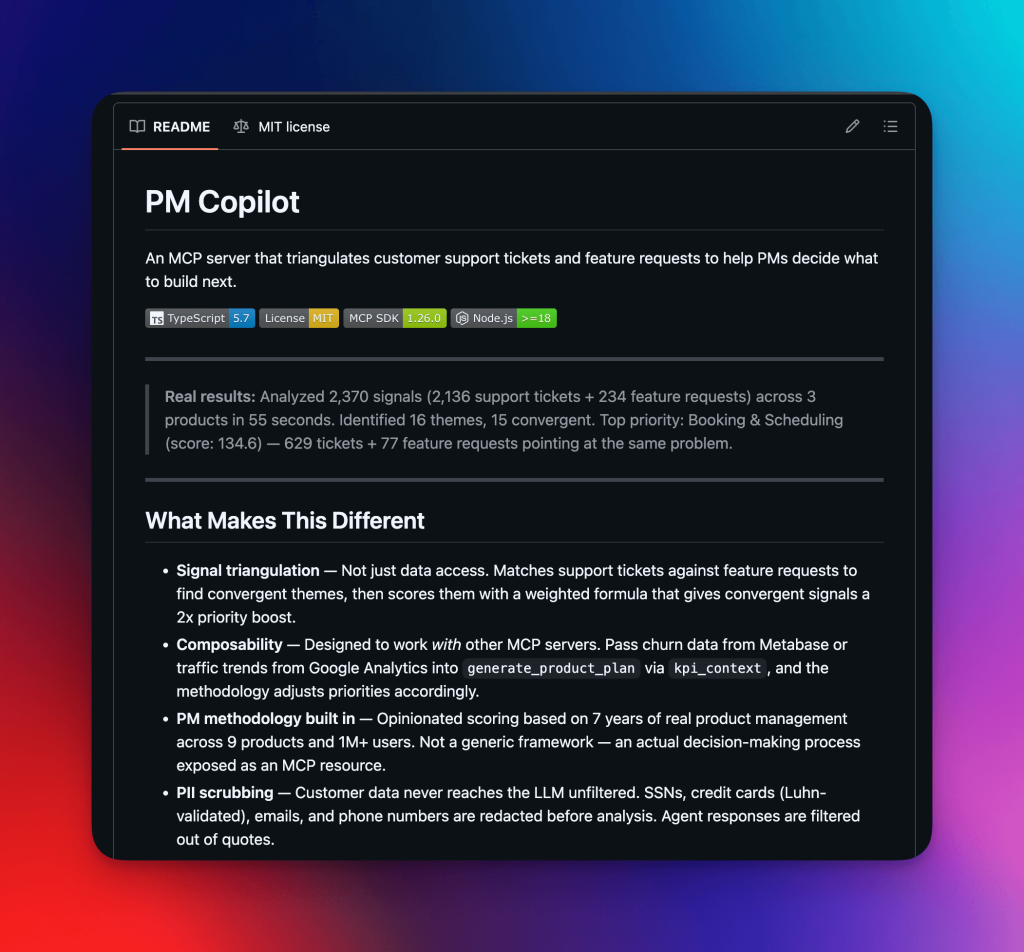
What I built
Here’s the output from a real run against live data from our three AppSumo Originals products:
Analyzed 10,424 signals (10,190 support tickets + 234 feature requests) across 3 products in 55 seconds. Identified 16 themes, 15 convergent. Top priority: Booking & Scheduling (score: 134.6) with 629 tickets + 77 feature requests pointing at the same problem.
The server connects to HelpScout and ProductLift, normalizes everything into a common format, matches it against configurable themes, and scores each theme using a weighted formula. The output is structured JSON that Claude synthesizes into an actionable product plan.
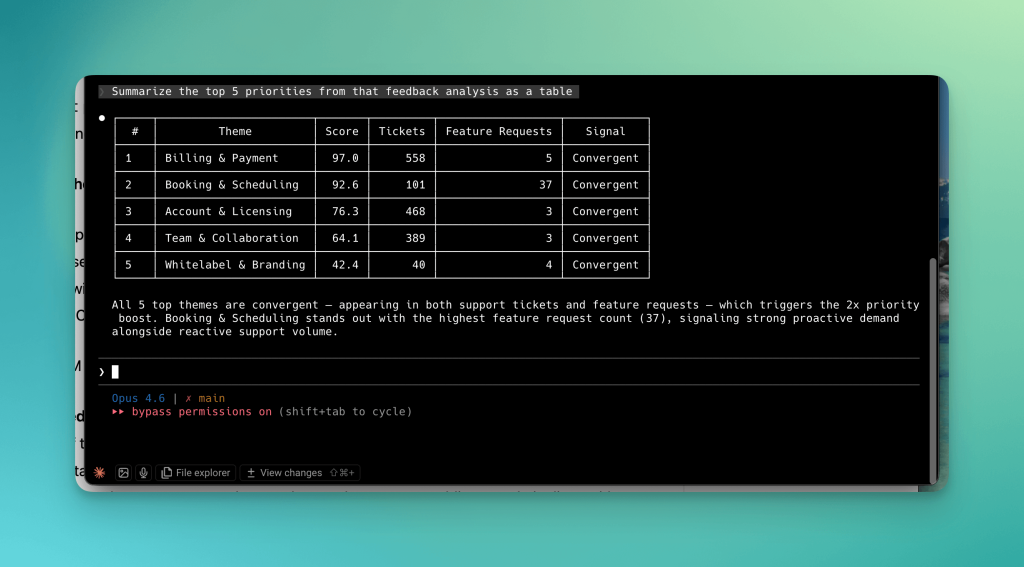
What’s interesting is what happens when you add business context.
Without business metrics, the formula says Billing & Payment is priority #1 (score: 91.1). It has the most raw signals (2,336 support tickets).
| # | Theme | Score | Tickets | Feature Requests |
|---|---|---|---|---|
| 1 | Billing & Payment | 91.1 | 2,336 | 20 |
| 2 | Booking & Scheduling | 87.1 | 682 | 74 |
| 3 | Account & Licensing | 69.7 | 1,955 | 8 |
| 4 | Team & Collaboration | 64.4 | 1,875 | 19 |
| 5 | Whitelabel & Branding | 50.2 | 92 | 30 |
But when I pass in real KPI data (like “TidyCal booking completion dropped from 74% to 66%. Churn increased from 3.1% to 4.2%.”), Claude reads the methodology, applies the override rules, and correctly moves Booking & Scheduling to #1.
With this example, it shows the core product is breaking, and churn is spiking. The formula’s ranking is wrong on its own, but the business context fixes it.
I designed the kpi_context parameter to automatically solve this issue, because I caught myself doing something the tool wasn’t built for. Every time I ran the analysis, I’d look at the output, check our Metabase dashboards, and mentally re-rank the priorities manually. The tool gave me the formula’s answer, but I kept overriding it with business context. So I built a parameter to make that override native.
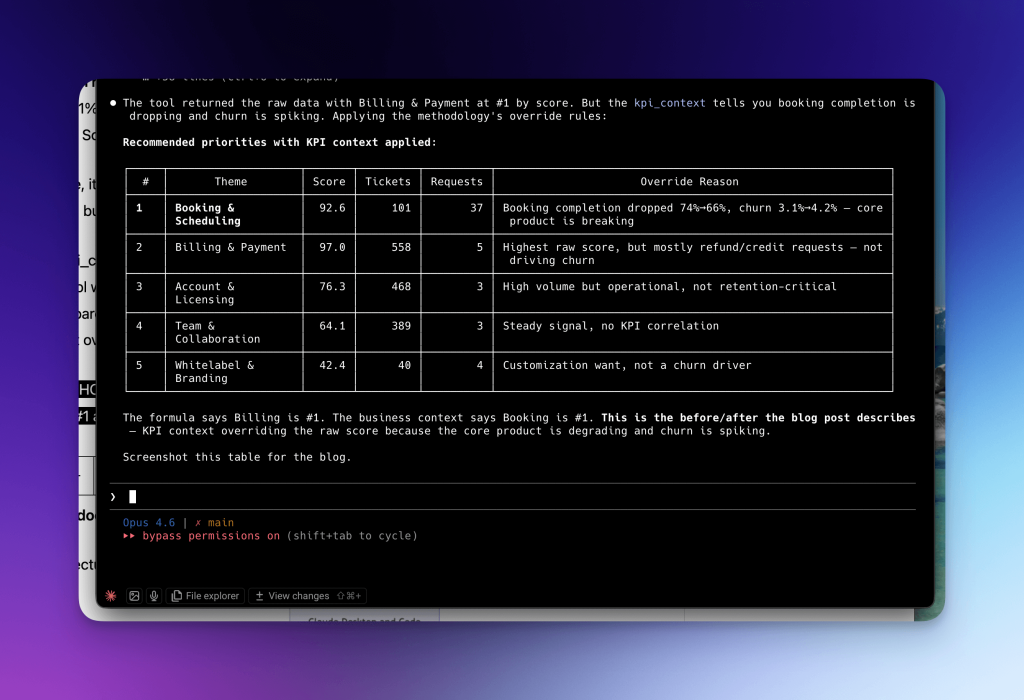
This is the before/after that matters. Not “I connected Claude to an API.” Every MCP server does that.
The question is: does the output change my decision and approach? In this case, yes.
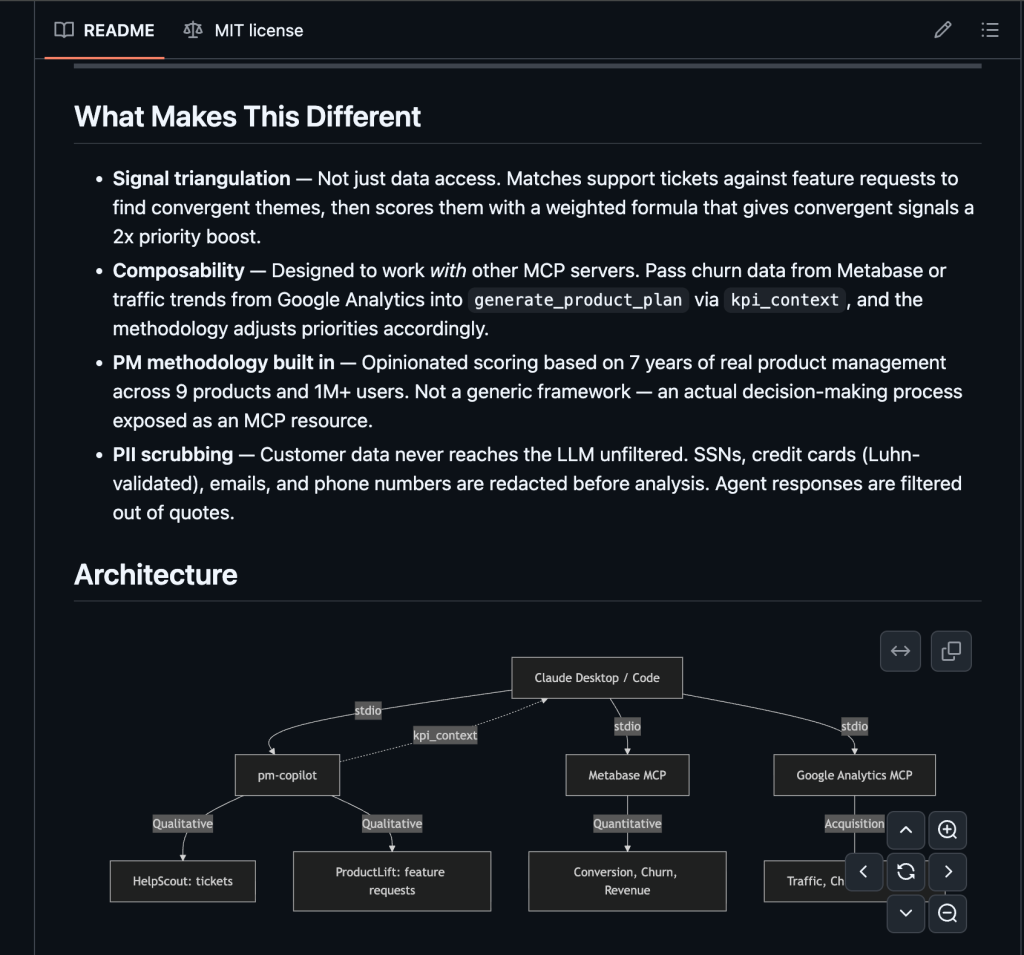
Here’s the architecture, including how I use it with other MCP servers:
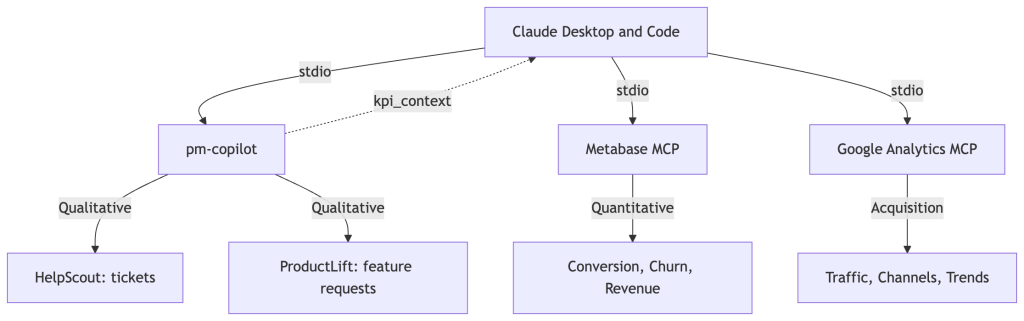
Claude orchestrates the calls. pm-copilot handles qualitative signals. Other MCP servers provide quantitative metrics. Nobody needs to know about each other.
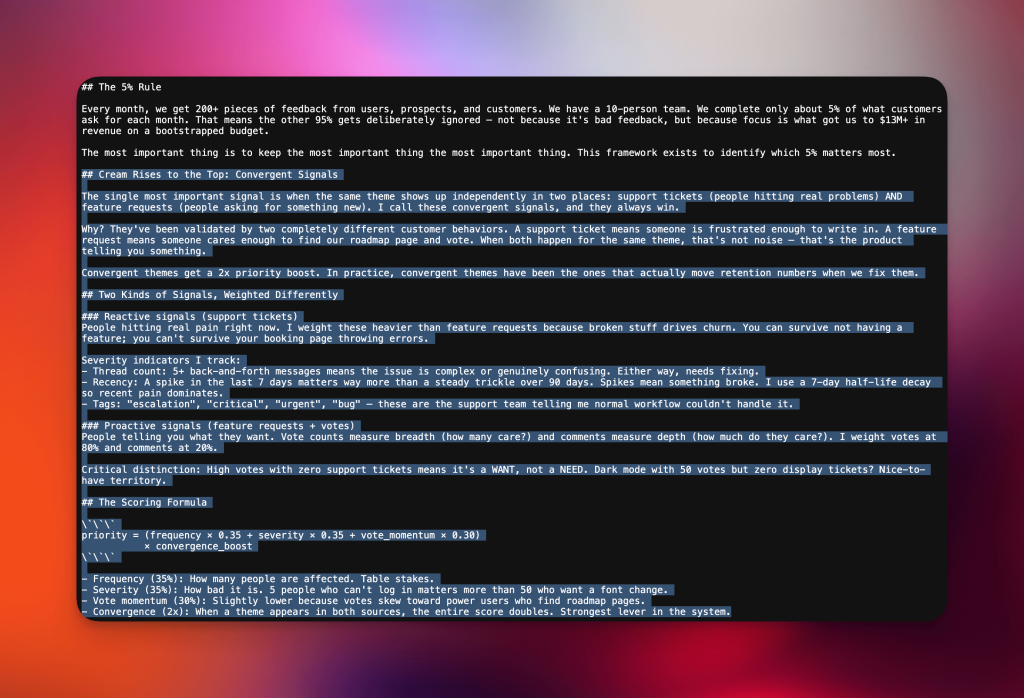
The 5% Rule: Why saying no IS the product
Every month, our team builds about 5% of what customers ask for.
We do that intentionally because focus is really, really important.
With a team of one designer and two backend devs, we ship 5-15 focused projects per product per month, and almost a hundred smaller update (Claude Code has been a game changer here; it’s literally 5x’d our output). We’re far from the days of one ambitious feature per quarter. Speed is so much more critical now than ever before.
One of my favorite sayings is the most important thing is to keep the most important thing the most important thing. As a Product leader, it’s really noisy when products grow. There’s more feedback, more data points, more avenues to explore. The methodology exists to identify which 5% matters most.
So here’s the framework I’ve built over 7 years of launching 9 products from zero to 1M+ total users:
First, convergent signals always win. A support ticket means someone is frustrated enough to write in. A feature request means someone cared enough to find our roadmap page and vote. When both happen for the same theme, that’s the “latent demand” that Claude co-creator Boris Cherny talks about.
Convergent themes get a 2x priority boost. In practice, these have been the ones that actually move retention when we fix them.
Second, reactive signals weigh heavier than proactive. Broken stuff drives churn. You can survive not having a feature. You can’t survive your booking page throwing errors.
I weight support tickets (reactive) equal to feature requests (proactive) in the formula, but severity scoring means a spike of recent tickets dominates steady vote counts.
Third, high votes with zero support tickets means it’s a WANT, not a NEED. Dark mode with 50 votes but zero display tickets? Nice-to-have territory.
This distinction is the one most PMs miss, and with limited time and resources it’s a forcing function that prevents you from building a much-requested feature that doesn’t move any metric that matters or that people actually use in reality. It’s important to separate out what really matters.
Fourth, business metrics override the formula. If TidyCal churn spikes from 3% to 4%, I immediately look at reactive signals. If booking completion is dropping, that’s the priority regardless of what the score says.
The formula processes the signal. The final call is still mine, and this the “art-and-science” to being a Product leader.
I’ve killed products with $1M+ invested when the signal wasn’t there. Sunk cost can’t drive prioritization. I still call 2-4 TidyCal customers per month, even at 350K+ users, because phone calls surface nuance that tickets and votes miss. Things like tone, workarounds people have built, adjacent problems they don’t think to report.
The scoring formula: (frequency × 0.35 + severity × 0.35 + vote_momentum × 0.30) × convergence_boost
I encoded this entire framework as an MCP resource so Claude can reference it automatically when generating product plans. It’s not a generic PM textbook. It’s how I actually make decisions, exposed as structured data that an LLM can reason with.
I chose to expose the methodology as a readable resource rather than hard-coding the scoring logic, because Claude applies better judgment when it can reason about the rules — not just follow them.
What MCP gets right (and where the ecosystem needs to go)
Building pm-copilot taught me more about the MCP ecosystem than reading docs ever could.
Here are observations from 20+ hours of building and testing, framed less as feature requests and more as product opportunities I think are worth building.
Composability is the killer feature nobody’s built for yet
The kpi_context parameter on generate_product_plan is a free-text string. It works whether the data comes from another MCP server, a Metabase query, or me typing numbers from a dashboard.
That flexibility is the point — and it’s what makes the before/after demo above work.
But right now, composability between MCP servers is held together with string passing. There’s no typed contract between servers. I can’t say “give me churn cohorts from Metabase, map to ProductLift themes, correlate with HelpScout ticket volume” as a declarative pipeline. I have to manually orchestrate each step through Claude.
This works for a PM who’s in the loop. But the ceiling is visible.
Imagine automated weekly product reviews where a scheduled workflow runs all three servers and posts a priority diff to Slack. You could imagine a ComposableContext type in the protocol that carries structured metadata between tool calls: Provenance, confidence scores, freshness timestamps. Servers could declare what context types they produce and consume, enabling typed pipelines without losing the flexibility of the current free-text approach.
As Boris says once again, that’s building for where the model will be in six months, not where it is today.
That future is close. But it’s not here yet.
PII in MCP needs an infrastructure-level answer
I built a PII scrubber into pm-copilot. SSNs, credit cards (with Luhn validation to reduce false positives), emails, phone numbers — all redacted before anything reaches Claude.

But every MCP server that touches customer data needs the same thing. And right now, each server implements this independently.
There are three ways to solve this:
Protocol-level: A pii_filter field in tool responses. Servers declare which fields contain PII, and the client scrubs before passing to the LLM. Advantage: zero per-server implementation cost. Disadvantage: servers must accurately declare PII fields, which is hard when the data is unstructured. Support ticket bodies contain unpredictable PII.
Middleware: A proxy MCP server that sits between client and servers. Intercepts all tool responses, runs PII detection, redacts before forwarding. Advantage: works retroactively on existing servers. Disadvantage: adds latency and a single point of failure. Also raises the question of who operates the middleware and what scrubbing rules they apply (this has governance implications).
Client-side: The MCP client (Claude Desktop, Claude Code, etc.) scrubs all tool outputs. Advantage: single implementation covers every server. Disadvantage: the LLM still receives raw data during the tool call processing step before the client can intervene, unless the architecture specifically accounts for this.
The right answer might be a combination: client-side scrubbing as the default safety net, with a protocol extension that lets servers declare PII-sensitive fields for additional handling.
What matters is that some solution exists at the infrastructure level, because the current “every server handles it independently” approach means most servers won’t handle it at all.
This isn’t a theoretical concern. My server processes customer support tickets that contain SSNs, medical information, and financial details. The distance between “interesting MCP demo” and “production tool a company trusts” is almost entirely a question of how PII flows through the system.
A “customer signal” standard would unlock an entire category
I built connectors for HelpScout and ProductLift. But every company has the same fundamental need: “What are customers saying across support, feature requests, reviews, NPS, and social?”
A normalized customer signal schema could look something like this:
{
"signal_type": "reactive",
"source": "helpscout",
"theme": "booking-scheduling",
"severity": 0.8,
"text": "[redacted customer message]",
"timestamp": "2026-02-15T...",
"metadata": { "thread_count": 7, "tags": ["escalation"] }
}With a standard like this, analysis tools (like pm-copilot’s scoring engine) could compose with any source — Intercom, Zendesk, Canny, app store reviews, NPS surveys — without building bespoke integrations.
The data source servers handle extraction and normalization. The analysis servers handle scoring and synthesis. You’d get an ecosystem where a PM installs a support-data server and an analysis server separately, and they just work together.
That’s the composability promise MCP makes. The ecosystem hasn’t delivered on it yet.
The tool I wish existed: an MCP Safety Scanner
Here’s a product that should exist and doesn’t: a tool that audits MCP servers for data safety before you connect them to your LLM.
Every MCP server has access to a transport channel with the LLM. Most servers are built by individual developers (like me) and installed via npx with full trust. There’s no equivalent of a permissions manifest, no sandboxing of what data a server can send back, no audit trail of what tool outputs contained.
Think about how mobile app stores work. You don’t install an app without the OS telling you what permissions it wants. MCP servers today are running with implicit full trust.
Imagine an MCP Safety Scanner that:
- Inspects a server’s declared tools and their parameter schemas
- Runs the server against test inputs and flags PII patterns in outputs
- Checks for prompt injection vectors in tool response content
- Verifies the server doesn’t exfiltrate data to undeclared endpoints
- Generates a trust report before you connect it to Claude
Does this exist? Leave a comment if it does. I couldn’t find one yet.
As the ecosystem grows beyond developer tools into enterprise workflows that handle customer data, this gap becomes a real attack surface. The server that helps companies trust the rest of the ecosystem is a meaningful product category.
What I learned building with Claude Code
I built this entire server with Claude Code across roughly 20 hours. I use it all the time, and it’s my favorite tech tool of the past 10 years. Here’s specific feedback from a power user’s perspective.
Where it exceeded expectations
Scaffolding speed was real. Six TypeScript modules, MCP tool/resource registration, PII scrubber with Luhn validation, theme analyzer with n-gram detection. All generated in one session across a few hours, all compiled first try. The ratio of “code that worked” to “code that needed fixing” was high.
Cross-file consistency was impressive. The shared fetchAndAnalyze() pipeline touches four files. Types, imports, function signatures stayed aligned across all of them without me having to remind Claude Code of interfaces. This is the kind of thing that breaks constantly with other AI coding tools.
Correction stickiness was high. When I corrected the pagination approach (it assumed Laravel-style, the real API used skip/limit/hasMore), the fix was applied correctly and consistently everywhere. When I said “skip thread fetching,” it understood the architectural tradeoff and implemented it cleanly.
The OAuth2 flow for HelpScout was handled end-to-end. Client credentials grant, token refresh, error handling — I gave Claude Code the HelpScout API docs URL and it generated working auth on the first try. This is the kind of boilerplate that eats an hour when done manually.
Where the DX has room to grow
The MCP server restart cycle is the biggest bottleneck. Change code, build, restart Claude Code, re-run tool, wait for API calls. Pretty annoying. Each iteration takes about 2 minutes. There’s no hot-reload path.
npm run build doesn’t affect the running server process. This caused confusion twice when I thought code changes were live but they weren’t.
The feature I want most is a watch mode that restarts the MCP server process when dist/ changes. This alone would cut iteration time roughly in half.
Real data reveals everything the happy path misses. The code “worked” for two full sessions before we tested with real APIs. Every major bug (wrong pagination, null preview crash, catastrophic thread-fetching performance) only appeared with live data.
The lesson is obvious in retrospect. But it suggests a product opportunity: a test harness that replays real API responses against MCP servers during development, so you find these issues before your first live run.
Tool output size is a fundamental tension. synthesize_feedback returns up to 563KB of JSON. Claude Code truncates this and writes to a temp file, requiring a second step to parse.
For a PM tool designed to return rich data, the tool output format conflicts with the LLM context window. I solved this with three detail levels (summary at 19KB, standard at 68KB, full at 563KB), but this feels like a protocol-level problem.
Servers need a way to return progressive detail. Where the client requests a summary first and drills into specific items as needed, rather than forcing a choice between “too little data” and “blown context window.”
It underestimates API call volume. Claude Code estimated 167 conversations when the real number was 2,134. It estimated “about 1 minute” for thread fetching when it was 4+ minutes.
For developers building API-heavy MCP servers, better heuristics around pagination depth and rate limiting would prevent the most common class of “it works on 10 items but breaks on 10,000” bugs.
Where this goes
The PM workflow is about to change fundamentally.
Right now, product management is 80% data gathering and 20% judgment. I spend days pulling signals from fragmented tools, normalizing them in spreadsheets, and building the context I need before I can make a single prioritization decision. The actual judgment — which 5% do we build this month? — takes hours and is the easiest part for me.
MCP inverts this ratio.
When servers for support data, feature requests, business metrics, usage analytics, and competitive intelligence all exist independently, a PM will compose them in a single conversation: “Here’s everything across all sources. What should we build this month?”
The data gathering drops to minutes. The judgment still takes hours, and it still requires a human who knows the business, talks to customers, and overrides the formula when the data is wrong.
That’s not a future where PMs matter less. It’s a future where the thing PMs are uniquely good at — judgment under uncertainty — finally gets the time and context it deserves.
And great Product people can help build and create with the development team at rapid pace to cut down on the lost-in-translation. These new responsibilities are already happening, and will only increase. I’m shipping dozens of PRs weekly to production for all our products.
pm-copilot is a working example of what that looks like today, with two data sources and a methodology that encodes 7 years of product decisions. The architecture supports adding sources, the composability pattern scales to any number of MCP servers, and the methodology is editable. Because no framework survives contact with a different product.
The code is at github.com/dkships/pm-copilot. MIT licensed. If you’re a PM drowning in fragmented customer data, try it. If you’re building MCP servers, think about composability, and think about safety.
The protocol gets the plumbing right. Now we need the ecosystem to build tools that actually compose, and infrastructure that makes them trustworthy.